To make things easier, here’s a downloadable checklist that you can use to implement these steps effortlessly.

Imagine yourself in a vast digital library, not filled with books but billions of web pages. Finding the exact information you need is a challenging task. Enter Google, your superhero librarian, who knows where information is stored.
So, how does Google do it?
Google uses “crawling” and “indexing” to organize the vast library. Imagine Google as a friendly spider gathering data from every corner of the web. It carefully notes what each page contains, much like flipping through every book in a library.
This data is then organized in Google’s massive “index,” a super-organized digital catalog, ensuring that when you ask questions, Google can present the most relevant information. Through complex algorithms, Google searches its index to find answers, considering the relevancy, credibility, and how other pages link to each content piece.
In this article, we will see how Google search engine works. We will see the three stages of the search engine principle.
Stage 1: Crawling
Look into the first stage of Google’s search magic: Crawling.
It is the initial step in Google’s quest to organize the world’s information. But how does it all begin? With crawling.
Let’s see what this crawling is and the techniques for web crawling.
What is Web Crawling?
Think of the Internet as an endless library. Crawling is how search engines start making sense of this enormous collection. It’s like having robots that act as explorers, traveling from one webpage to another using links. These bots are on a mission: to find new pages and update old ones. It’s their way of mapping the digital universe, ensuring no new blog post or website update slips through the net.
Any content, including text, web pages, images, PDFs, and more, will be crawled. By following the links, web spiders crawl the contents despite their format. When search engine bots discover and crawl new web pages, they categorize and add them to the individual search engine’s directory. For example, in Google, Google bots store to Google Index.
Techniques for Efficient Web Crawling
Getting Google to crawl or re-crawl your pages more quickly can significantly boost your website’s visibility and search engine ranking. Here are some effective strategies tailored to enhance the efficiency of web crawling for your site.
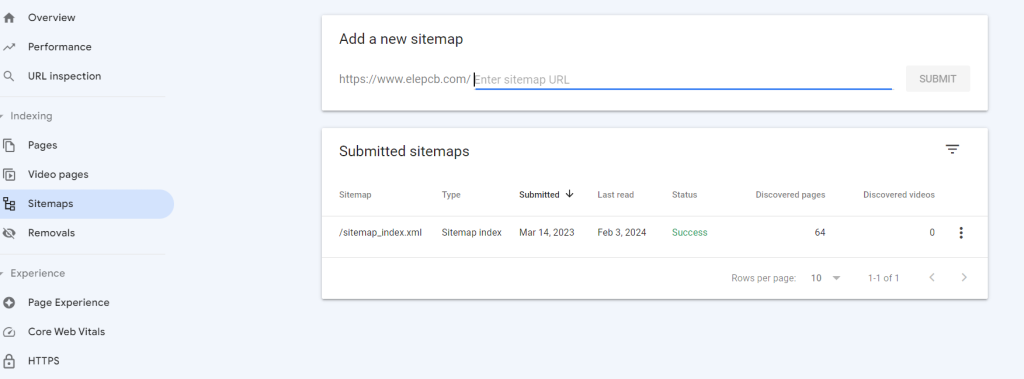
Submit Your Sitemap
Share your website’s layout with Google through Search Console. It’s like handing over a map, ensuring Google can navigate your site efficiently. Update this map whenever new content is added to keep things current.
In this way, you can let search engine bots crawl your web pages quickly.
Robots.txt
Search engine crawlers can freely explore every web page on the Internet. However, allowing Google bots unrestricted access to all pages, including duplicates and less crucial ones, can exhaust your crawl budget.
This means Google might delay crawling your vital pages, impacting their indexing.
Persistent issues of this kind can hamper your site’s crawl efficiency, causing Google bots to take longer than usual to visit or revisit your pages. Addressing this promptly is crucial for your website.
Improving crawling speed involves highlighting important pages and indicating which parts to skip. Utilizing the robots.txt file grants some control over the bots’ crawling behavior, aiding Google in navigating your site more efficiently.
Optimize Internal Linking
Imagine your website as a connected web. Smartly linking your pages guides Google through your content, like creating clear signposts for smooth navigation. It will help the crawler to discover and crawl your new linking pages smartly.
Improve Page Load Speed
Nobody likes waiting, not even Google. You have to increase your website’s loading time through image optimization and caching so it loads faster.
Build Quality Backlinks
Backlinks are like trustworthy recommendations. If reputable sites vouch for yours, Google sees it as a vote of confidence, increasing visibility.
Update and Refresh Content
Treat your website like a garden. Regularly update and add fresh content, signaling to Google that your digital garden is always in bloom.
Refer to Official Documentation
Follow Google’s rules by checking their official documentation on crawling and indexing. It’s like having a guidebook for playing the SEO game.
Stage 2: Indexing
What is Search Engine Indexing?
Search engine indexing is a crucial step in the online world. Think of it as the librarian’s job in a vast library called the Internet. When you search for something, engines like Google organize information beforehand to respond to your queries swiftly. Once a web crawler discovers a page, indexing kicks in. It’s like the librarian cataloging a book – analyzing and storing its details for quick retrieval.
How to index your content faster?
Now, to speed up getting your content into this digital library:
Use Google Search Console
Think of it as chatting directly with the librarian. Submit your website or new content through Google Search Console to let Google know there’s something fresh to be cataloged.
Ensure High-Quality Content
Quality matters in this library. Search engines love valuable, original, and engaging content. Ensure your content provides useful information or answers specific questions – it’ll get indexed faster.
Improve Site Structure
Imagine a well-organized library with clear sections and easy-to-follow signs. Apply the same to your website. A clean hierarchy and text links help search engines index your content efficiently. Every page should be reachable with just one click.
How do you Know if Your Site is Indexed or not?
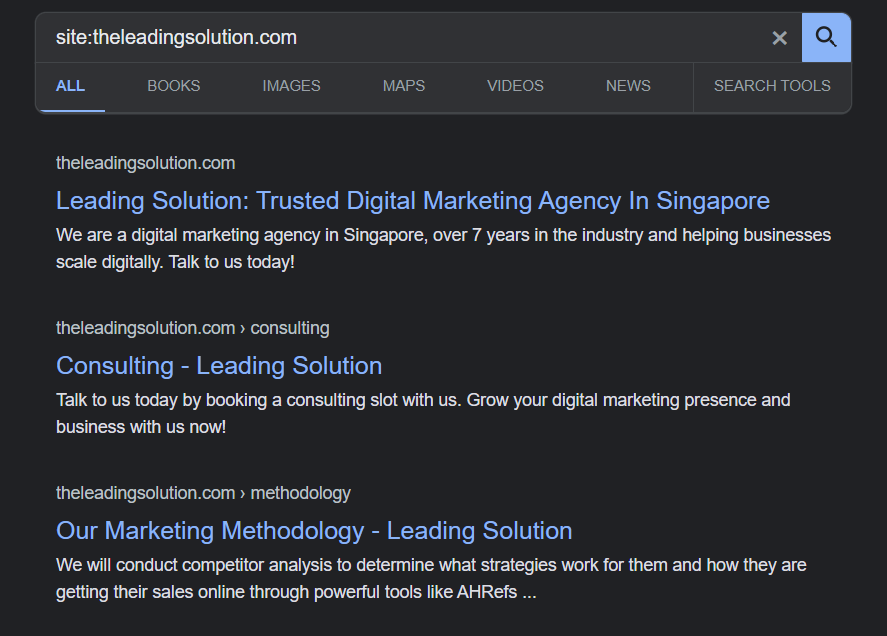
To confirm whether your website is indexed or not, you can visit Google and perform,
Site:yourwebsite.com. For example,
Site:theleadingsolution.com will display all the pages of your website that are indexed in Google search engine.
Alternatively, you can also use Google Console to check your indexed pages.
Stage 3: Ranking
What is Search Engine Ranking?
Imagine search engine ranking as a virtual popularity contest – your website competing for attention on the search results stage. Google, playing the judge, decides where your site lands when someone searches for related terms.
Once the web is explored and cataloged in crawling and indexing, ranking comes into play, determining who shines. Complex algorithms assess each page’s relevance and authority. They weigh factors like content quality, reputable site links, and user-friendliness.
Suppose someone searches for “best coffee shops in Singapore“, the engine finds and ranks pages matching the query.
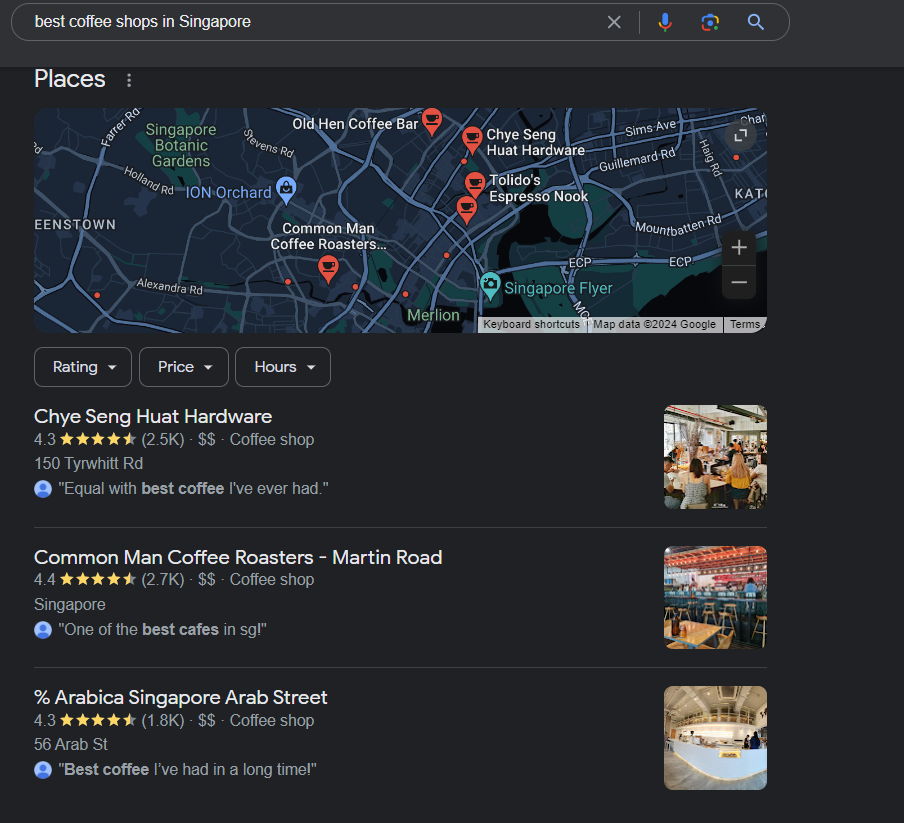
Ranking is the critical factor to your site’s visibility. A higher rank means more people discover, click, and potentially become customers or followers. It’s vital to connect your content with the audience actively seeking it, making optimizing these rankings crucial for website success.
Improving your website ranking is crucial for boosting visibility and attracting more website visitors.
Strategies to Rank Your Website Faster
Below are some practical tips to consider to enhance your website ranking:
OnPage and OffPage SEO
On-page SEO factors like headings, title tags, meta tags, content optimizations, and off-page SEO factors like building backlinks should be considered. This will help to boost your site ranking.
Quality of Content
Creating high-quality, engaging, and user-engaging content is critical for achieving top rankings. However, understanding what your audiences are looking for is essential. After all, there is no use in creating content that no one wants to read.
To address this, undertake targeted keyword research to determine what customers want from businesses like yours. Narrow down your keywords based on search volume and competition. You can use tools like SEMrush, Ahrefs, and more.
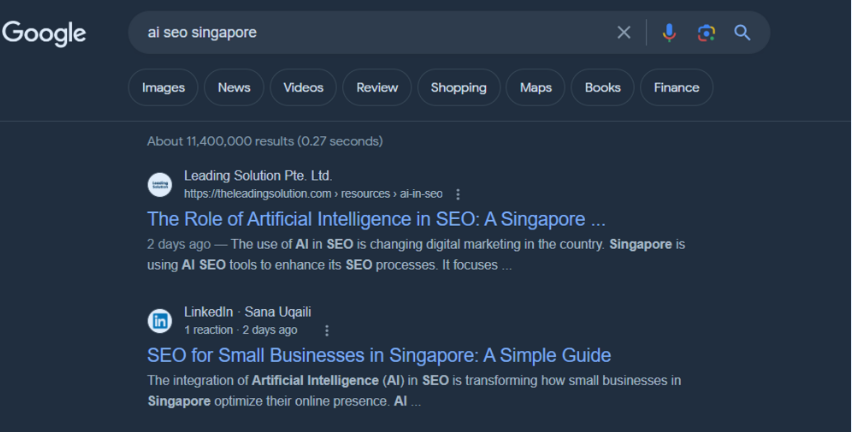
Then, brainstorm the content ideas based on your keyword result. Ensure your content provides value and relevant information based on user searches. It also helps to establish you as a valuable authority in your field.
As Google recognizes your authority in the subject, your search engine result page (SERP) ranks will likely improve significantly.
Search Intent
Search engines want to give people the best answers when people search online.
Let’s say you have a fitness equipment website. If someone looks for “effective home workouts,” don’t just show them products. Make guides and blog posts with workout tips and advice on creating a home gym.
Users want helpful information, not just a sales pitch. Understand what they’re looking for, and you’ll rank higher in search results.
It’s the same idea when people search for a smartphone – they prefer pages that help them decide. So, focus on the user’s search intent and you’ll do better on search engines.
You can use tools like askthepublic, and Semrush to find the related questions and topics people are searching for.
Technical SEO
If you ignore the technical stuff in search engine optimization (SEO), your website’s ranking can take a hit.
Pay close attention to the SEO details. This includes fixing broken links, adding canonical tags, removing duplicate content, improving page speed, and more.
It’s not just for the search engines – it’s like cleaning up backstage to ensure everything runs smoothly for both the performers (search engines) and the audience (users). Keep it tidy for a hassle-free experience!
Conclusion
Google and other search engines aim to provide relevant information to their users. They do it by navigating and displaying the output through search engine pages. To build a strong online presence, understanding the principle of web crawling, indexing, and ranking factors is crucial.
If you are looking for a top-notch search engine SEO agencies in Singapore? The Leading Solution has got you covered! Boost your website’s visibility and get the results you’re aiming for. At Leading Solution, we specialize in delivering exceptional AI SEO services tailored to your unique needs. Whether you’re seeking an experienced SEO agency for top-tier SEO servicesor a trusted partner for e-commerce SEO, our team is here to help. We also offer local SEO servicesto boost your visibility within your community and web development expertiseto create stunning, functional websites. Explore our SEO packages in Singaporeto find the right solution for your business goals. Let’s work together to achieve success online.
FAQs
How do search engines rank my webpage?
Search Engines rank webpages based on various factors in order to provide the most relevant and valuable results to the users. The most common factors that determine your website ranking include:
- Relevance of webpage content
- Quality, originality, and uniqueness of information
- Site Speed and mobile friendliness
- Quality backlinks on the website
- Secure and accessible websites
How does Google decide the indexing page after crawling?
Googlebot, which is Google’s crawler, is used to find public web pages. Then, based on factors like freshness, content quality, user search queries, and keywords, the pages are indexed.
However, if the content seems duplicated or it contains directives in the robots.txt file, it will be hard to index it.
How does robots.txt file improve my website’s crawling?
A robots.txt file informs search engine spiders what pages or files they may and cannot request from your site.
To improve your website’s crawling:
- Use the Disallow directive to prevent search engines from crawling specific parts of your site (e.g., admin pages).
- Use the Allow directive (for Googlebot) to specify what can be crawled, especially if you have previously disallowed sections.
- Avoid using robots.txt to hide low-quality content; improve or remove such pages instead.
- Ensure your robots.txt file doesn’t block essential pages or resources that affect page rendering.
What are some common mistakes to avoid in search engine optimization?
Common SEO mistakes to avoid include:
- Ignore title tags and meta descriptions or stuff them with keywords.
- Using excessive and irrelevant keywords (keyword stuffing).
- Mobile optimization and page speed need to be improved.
- Creating low-quality, duplicate, or thin content.
- Failing to include structured data markup.
- Not leveraging the power of internal linking.
- Ignoring the importance of local SEO (for local businesses).
What is backlinks in SEO?
Backlinks are links that connect one website to another. They are essential for SEO since they indicate to search engines that other websites support your material. High-quality and relevant backlinks can help to rank the webpage and enhance visibility in search engine results pages.
How does the search engine algorithm work?
An algorithm used by search engines searches the Internet for billions of web pages and finds, indexes, and ranks them. When a search query is entered, the algorithm sifts through the index to return the most relevant and accurate results based on several criteria, including site authority, keyword relevance, user experience, and page content quality. These algorithm in search enginges are constantly updated to deliver consumers the most accurate and valuable results.
Difference Between crawling and indexing
| Crawling | Indexing |
| The process where search engine bots (crawlers or spiders) navigate and explore web pages to gather information. | The process of storing and organizing the information collected during crawling into a searchable index. |
| Focuses on discovering and fetching web pages, following links, and updating the search engine’s database with new content. | Involves analyzing the content of web pages, extracting relevant information, and cataloging it for efficient retrieval in response to user queries. |
| Ongoing and continuous, as search engines regularly revisit websites to ensure their index is up-to-date with the latest information. | Typically, it occurs after crawling; the frequency depends on the importance and update frequency of the content on a particular webpage. |
About The Director
Notable Achievements


Struggling to Attract More Traffic?
Let us help! We provide various digital marketing services that can easily rank your website on the first page of Google such as:
Allow your website to be seen by more users by scheduling an appointment with us today!